透過MATLAB與Simulink整合自動化機器學習與DevOps
當有更多的組織機構開始仰賴機器學習應用來協助他們處理核心事業職責,也有許多正更進一步地審視這些應用的完整生命週期。對機器學習關注焦點已從最初的開發部署擴展到環繞著持續監管與更新。輸入資料的改變有可能會降低模型的預測或分類準確性,及時的再訓練與模型評估有助於產生更好的模型與更精確的決策。
在機器學習的運行(machine learning operations,或ML Ops),開發的規劃、設計、建構、及測試活動與運行時的部署、操作、及監管活動是以持續的回饋迴圈連結在一起(圖1)。許多資料科學團隊已經將ML Ops循環之中的一部分自動化,像是部署及運行。
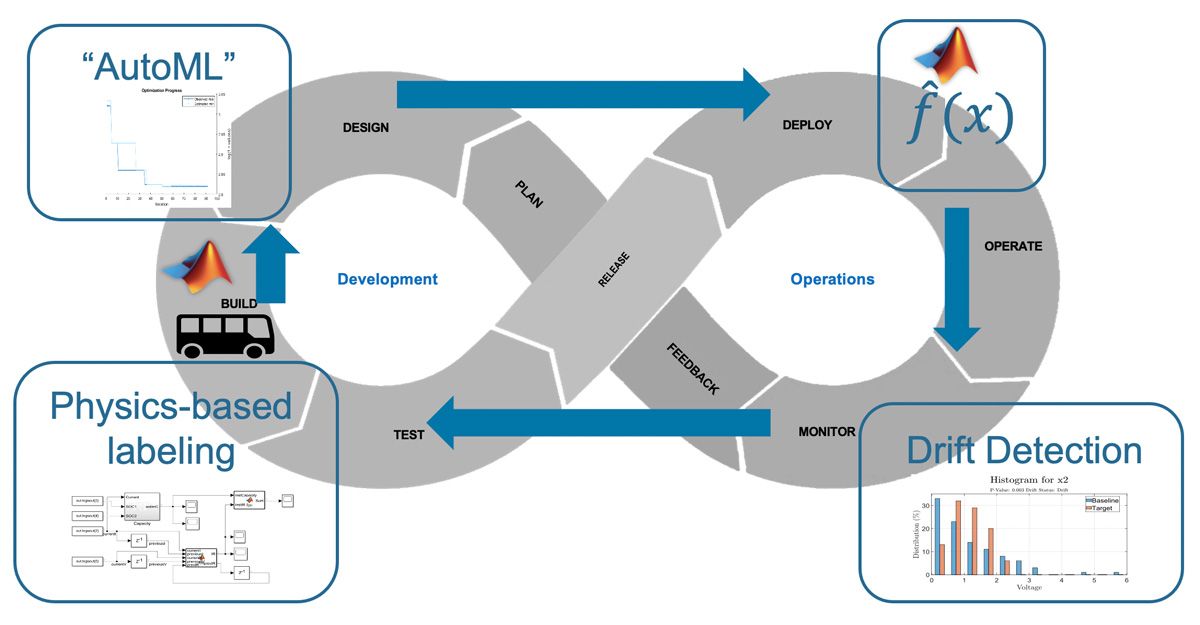
然而,完整循環的自動化需要額外的步驟:監督與評估模型表現、將評估結果併入表現更好的模型、並且重新部署新的模型。實現這樣的自動化具備幾項重要的好處,讓資料科學家可以將更多時間花在設計有用的機器學習解決方案,減少在IT行政與繁瑣、容易出錯的手動任務上面花費的時間。
為了說明以MATLAB®和Simulink®進行基於模型的設計(Mode-Based Design)可以如何使用在自動化ML Ops流程,我們實現一個虛構的都會運輸系統預測性維護應用。某個機構組織需要一種方法,在他們的電動巴士車隊的電池出現在行進過程中發生故障的風險之前,預先規劃電池的維修或替換。
這項應用內有一個機器學習模型,它使用電池充電狀態(state of charge,SOC)、電流、以及其他的量測值來預測電池的健康狀態(state of health,SOH)。其他幾個元件包含一個負責執行大規模機器學習模型的應用伺服器,一個將觀察到的資料與訓練資料做比較的漂移偵測元件,它被用來判斷是否有重新進行訓練的必要,還有一個高逼真度的電池物理模型來協助自動化標記觀察到的資料。
對於許多組織來說,最後一個元件–高逼真度的物理模型–是落實完全自動化所缺少的一塊。少了這個物理模型,會需要由人類來檢視觀察到的資料並且加上標記;而有了它,這項基本的步驟以及完整的ML Ops循環就可以被自動化。
建立模型來進行電池資料的生成及自動標記
在可以開始訓練深度學習模型來預測電池的健康狀態之前,我們需要先有資料。在某些情況下,機構組織可能已經擁有從運作於真實世界系統收集來的資料。另一些則會需要藉由模擬來產生資料,這也包括我們的虛構運輸系統。
為了要產生運輸網路電池系統的訓練資料,我們透過Simulink和Simscape™建立兩個以物理為基礎的模型。第一個模型納入來自電氣和熱領域的動態,產生真實的原始感測器量測值,包含電流、電壓、溫度和SOC(圖2)。第二個則以第一個模型產生的量測值推導出的電池估計容量和內電阻來計算SOH。第二個模型可幫助我們自動標記觀察到的資料,大幅減低再訓練迴圈所需要的人力介入。
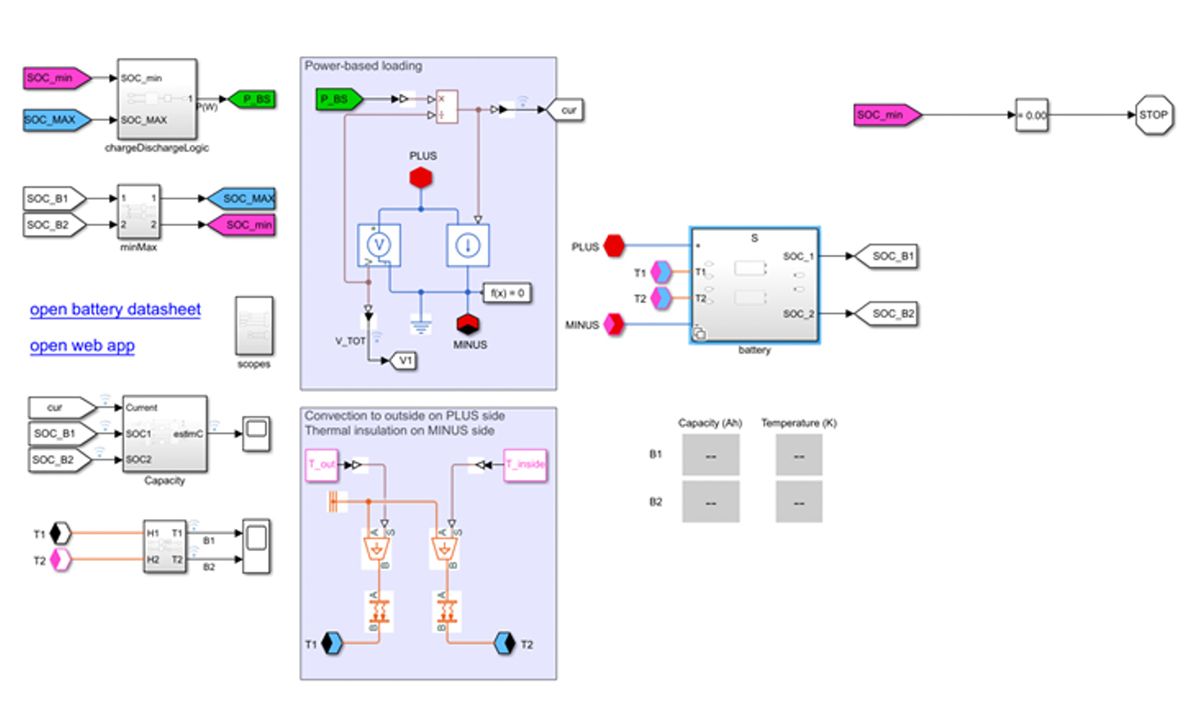
藉著對各個電池採用獨立的老化曲線和變更第一個模型的週圍溫度輸入值,我們為一組大型的車隊建立了一個歷史資料集,該資料集適合用來訓練我們的預測性維護機器學習模型。
建立及部署ML模型
有了用來訓練的資料時,我們便將注意力轉移至ML模型。我們使用Diagnostic Feature Designer app來探索原始量測值,擷取多域特徵,並選擇出具備最佳狀態指示器的特徵集。由於我們的目標是要自動化整個循環,因此模型的選擇與訓練也需要被自動化。為此,我們建立一個稱為AutoML的元件。這個元件是在MATLAB裡面使用Statistics and Machine Learning Toolbox™建立的,負責自動地找出對於一組給定的訓練資料集之最佳機器學習模型和最適超參數。AutoML元件也作為循環的起始:它從原始的訓練資料和我們的特徵集產生內部的機器學習模型。
除了支援向量機(support vector machines)之外,這個AutoML元件還訓練並評估線性迴歸模型、高斯過程迴歸模型(Gaussian process regression models)、提升決策樹(boosted decision trees)的集合、隨機森林(random forests)、以及完全連接前饋神經網路。
當AutoML流程完成,我們使用MATLAB Production Server™將一個最適模型部署到我們的企業內部(on-premises)生產環境。
資料漂移的判斷與處理
許多機器學習有個問題是裡面包含了一個隱藏的假設,就是使用來訓練模型的資料可以完整代表整個特徵空間的基本分佈。換句話說,會做出資料的分佈不會變動的假設。但在真實世界卻不總是這樣。舉例來說,在我們的電動巴士應用,我們可能已經做了車輛會在特定溫度範圍運作的假設,並且訓練了我們的模型。然而在生產階段,我們卻發現巴士經常會要在比該範圍還要高的溫度下運作。這種資料上的改變被稱為漂移(drift)。而隨著漂移的增加,模型的預測準確度通常會降低。因此,資料科學家通常需要偵測資料隨著時間產生的變化並做出反應,通常是訓練新的模型。
這時,重要的是要區別出概念(concept)漂移和資料(data)漂移。在機器學習領域,概念漂移被定義為觀察到的特徵與標記或回應的聯合機率隨著時間的變化。概念漂移可能很難被使用在已經是生產階段的機器學習模型,因為特徵值及回應值都必須為已知。因此,許多機構組織把注意力放在下一個最佳選擇:資料偏移,也就是只有發生在觀察到的特徵上的變化,而不包含標記。這也是我們採用的方法。
我們開發一個MATLAB應用來偵測漂移,該應用能夠將新觀察到的資料值與模型訓練資料集的值做比較。
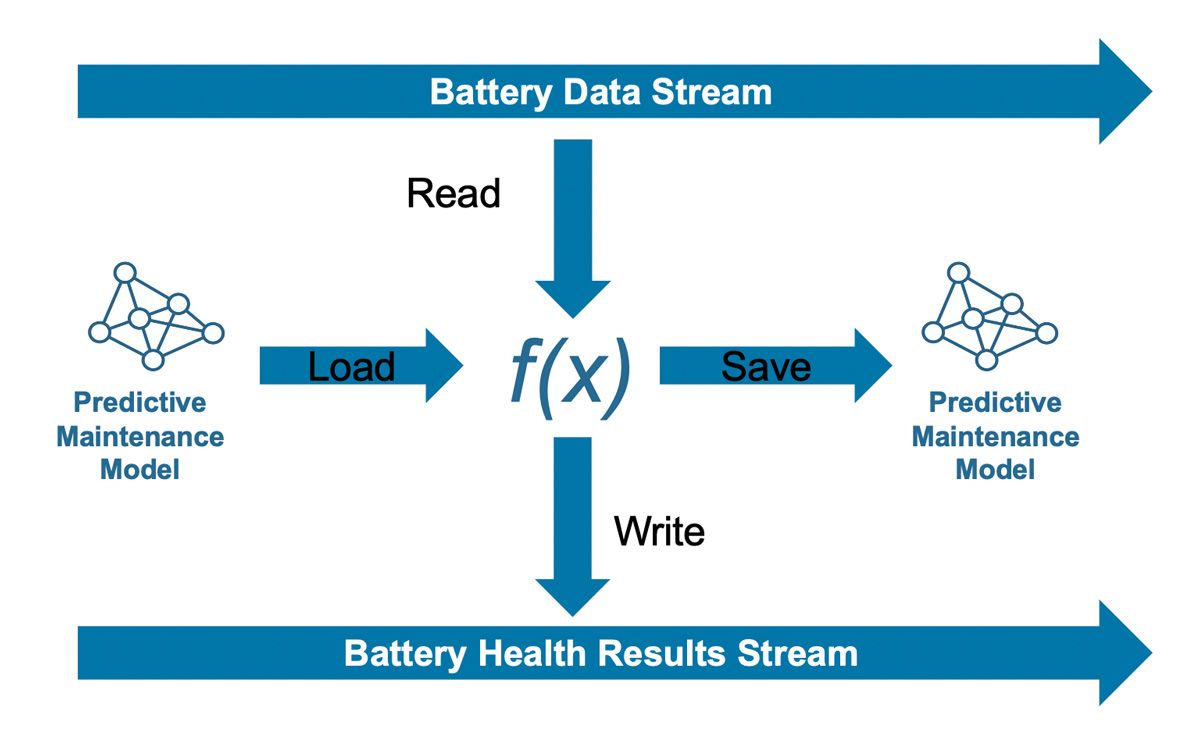
在生產階段,這組應用幾乎即時地從一個Apache® Kafka串流讀取觀察到的資料,並且透過一支處理使用機器學習模型所得到的觀察的MATLAB函式做出電池的健康預測(圖3)。我們使用MATLAB Production Server的Streaming Data Framework開發MATLAB函式,這可以幫助我們從在檔案中處理歷史資料輕鬆轉換為在Kafka資料流的即時資料。因為完整的資料流超出記憶體的容量,這個架構會透過一系列的迭代處理串流資料。每一個迭代包含四個步驟:從資料流讀取一批觀察數據、裝載模型、做出預測並編寫至輸出資料流,以及如果必要的話會把任何需要的資料儲存下來供下一次迭代使用。每一個批次的尺寸會延伸到長度足夠的時間區間,以確保擷取出來的特徵捕捉到充分的電池特性來進行有效的SOH預測。
要注意,即使漂移偵測應用判斷觀察到的資料出現顯著變化,也不見得代表機器學習模型已經過時。在這項應用獲得透過基於物理的SOH模型傳遞的新資料而獲得新觀察資料的回應值(或標記)之前,它並不能決定模型是否過時。這時,該應用可以將從以物理為基礎的模型得到的回應值與從機器學習模型得到的回應值做比較;如果兩者之間差異顯著,則可以調用帶有新資料的Auto ML元件,並且自動地建立一個針對來自車隊的新資料進行過優化的新機器學習模型。
也許會有如果我們可以在一開始就透過模擬來估計電池的健康狀態,為什麼還會需要機器學習模型這樣的疑問。答案是,ML模型可以接近即時產生預測結果–比起以物理為基礎的模擬的速度快上許多。
一個可擴展、普及化的架構
我們為自動化ML Ops所設計的這個架構是可以水平擴展的。預測與監督元件皆執行在MATLAB Production Server上,模型的預測則是透過MATLAB Parallel Server進行(圖4)。這個架構也可以被普及化。雖然我們的範例聚焦於電動巴士的預測性維護與漂移偵測,這個架構可以輕鬆地被改編套用於其他應用或使用情境。舉例來說,以物理為基礎的Simulink模型可以用在MATLAB開發的數值模型取代。同樣地,許多我們使用的現成元件–如使用於資料串流的Apache Kafka、使用於儀表板架構的Grafana–可以被其他原生於雲端的服務取代。
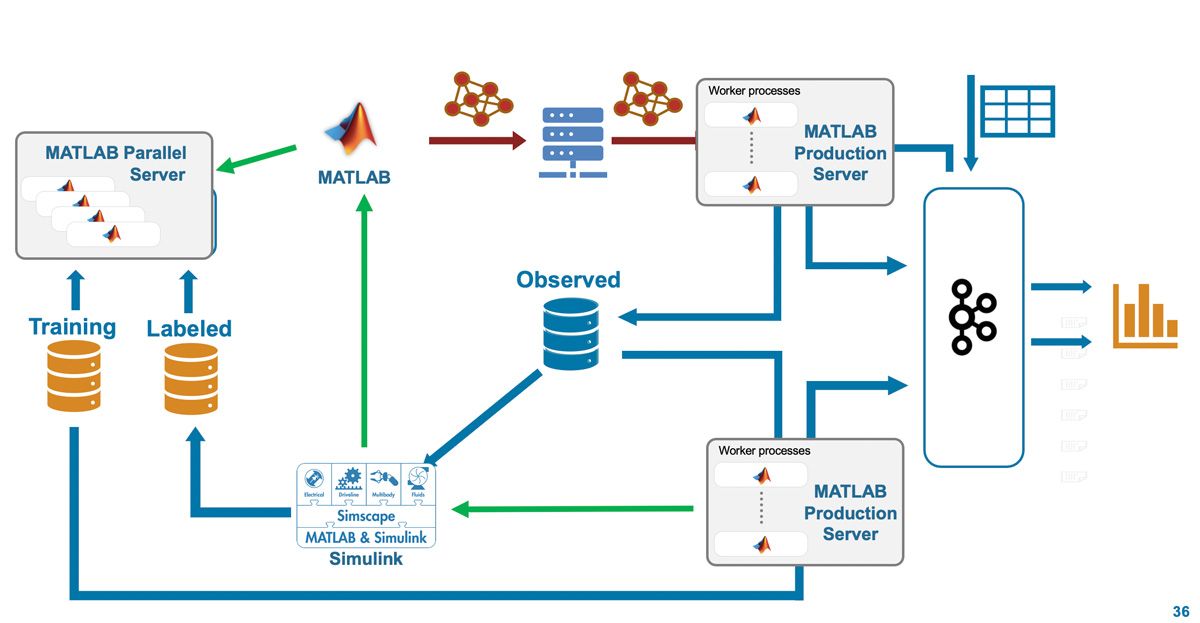
使用現成的元件可幫助我們專注於架構而不是執行上的細節,就像一個完全自動化的ML Ops循環協助資料科學家專注於設計機器學習解決方案,而不是管理IT行政的繁瑣細節。